Flat File 端口
Version 25.3.9418
Version 25.3.9418
Flat File 端口
Flat File 端口可以实现平面文件和 XML 文件的互相转换。
概述
每个 Flat File 端口配置一个特定的平面文件格式,从而实现与 XML 格式的互相转换。Flat File 端口有两个主要的模式:
-
Position Delimited,端口配置有任意的字段名称、索引(即位置)和长度,表明数据在平面文件中每一行出现的位置。
-
Character Delimited,端口配置有分隔平面文件中字段值的字符。
更多详情请查阅定义平面文件格式部分。
注意:如果还需要一个数字控制字段。请按照 非标准 XML 控制字段 中的说明进行设置。
Flat File 端口支持定义多种平面文件中不同类型的行。例如,平面文件中可能有一个 “header” 行,代表订单的日期,有多个 “item” 行,代表订单中的行项目。
定义多种行类型的关键是指定控制字段;控制字段值决定了在平面文件中特定的行类型(例如,header 行可能有一个控制字段值为 “HEAD”,item 行可能有一个控制字段值为 “ITEM”)。更多配置多种行类型的详情请查阅多种行类型部分。
平面文件格式配置完后,端口会转换与此格式匹配的文件到 XML。最终的 XML 结构在 XML 格式部分有详细解释。Flat File 端口也可以将匹配这种结构的 XML 转换为定义的平面文件格式。
某些平面文件在不同行有隐含的上下级关系。关于更多在转换平面文件为 XML 时而保留上下级关系的详情,请查阅多行层级关系部分。
端口配置
设置
配置
与端口关键配置有关的设置。
- 端口 Id 端口的静态、唯一标识符。
- 端口类型 显示端口类型及其用途的描述。
- 端口描述 一个可选字段,用于提供端口及其在流中的角色的自由格式描述。
- 文件类型 Position Delimited - 平面文件中的字段显示在每一行的特定位置。
Character Delimited - 这个属性需要指定特定的分隔符。 - 分隔符 如果文件类型设置为 Character Delimited,则表示平面文件中用于分隔各个字段的字符。
控制字段:位置分隔
和控制字段有关的设置,决定了在平面文件格式中定义的不同的行类型。
- 多行模式 平面文件是否包括多种行类型。更多信息请查阅多种行类型部分
- 起始索引 如果多行模式启用,该值就是行中控制字段开始的索引。例如,如果某一行中的第一个字段定义了行类型(即第一个字段是控制字段),那么起始索引就是 0。
- 控制字段长度 (可选)如果多行模式启用,这个值定义了从起始索引开始读取控制字段的长度。
- 当前列标题 如果不启用多行模式,这个设置则决定了平面文件中的第一行是否应该被解析为列标题(即每个字段的名称而不是实际的数据)。同样的,启用这个设置,就会使得端口在将文件从 XML 转换为平面文件时生成一个标题行。
控制字段:字符分隔
和控制字段有关的设置,决定了在平面文件格式中定义的不同的行类型。
- 多行模式 平面文件是否包括多种行类型。更多信息请查阅多种行类型部分
- 字段索引 如果多行模式启用,该值就是行中(索引从 0 开始)控制字段的索引。例如,如果某一行中的第二行定义了行的类型(即第二行是控制字段),那么字段索引就是 1。
- 生成字段/行类型名称 如果多行模式启用,那么该设置提供了一个选项,在平面文件中 不 指定字段和行的名称和索引。当启用这个设置,端口将会自动为下面行类型中没有明确定义的字段和行生成 XML 元素。
- 当前列标题 如果不启用多行模式,这个设置则决定了平面文件中的第一行是否应该被解析为列标题(即每个字段的名称而不是实际的数据)。同样的,启用这个设置,就会使得端口在将文件从 XML 转换为平面文件时生成一个标题行。
- 使用自动生成的字段名称 如果多行模式没有启用,这个设置决定了端口是否生成通用字段名称。不启用该选项,在行类型部分手动指定字段名称。
行类型
该部分允许以平面文件格式定义字段名和位置(如果文件类型是 Position Delimited)。更多定义平面格式的详情请查阅定义平面文件格式部分。
如果多行模式启用,使用添加行类型按钮定义。每个行类型有一个控制字段,来标识行类型。例如,header 行可能有值为 HEAD 的控制字段,item 行可能有值为 ITEM 的行。
如果文件类型设置为 Character Delimited,多行模式启用,生成字段/行类型名称 启用,那么为平面文件中存在的所有字段和行类型提供名称和索引就不是必需的。
高级
- 填充字符 当创建平面文件但字段值不能填满整个字段长度时,这个字段会被用来填满剩余部分。
- 无效的XML名称前缀 某些字段名对于 XML 元素时无效的(例如,以数字开头的字段像 “123ABC”),所以在从平面文件生成 XML 时必须设置一个前缀。同样的,当从 XML 转换 平面文件时,端口会查找该前缀并去除它。
- 行分隔符 指定行与行之间的分隔符。选项为 LF (默认) 和 CRLF。
- 本地文件名格式 用于为端口输出的消息分配文件名的方案。 可以在文件名中动态使用宏来包含标识符和时间戳等信息。 有关详细信息,请参阅宏。
- 嵌套行类型 该设置仅在从平面文件转换到 XML 文件时,且在平面文件中有多种行类型时才相关。如果多行模式启用,端口将会根据平面文件的控制字段行(即定义行类型的字段)增加层级关系到最终的 XML。更多关于该自动层级关系请查阅多行层级关系部分。
- 行尾填充 默认设置下,端口会在遇到异常的行尾时抛出错误。当启用时,该设置告知端口填充端口而不是抛出错误。
- 始终使用单元格分割符 如果文件类型设置为 _Character Delimited_时,打开此设置以使端口始终使用单元格分隔符(
")包装所有值,关闭此设置后端口仅会包装还有分隔符的值。 - 延迟处理 放置在输入文件夹中的文件的处理延迟的时间量(以秒为单位)。 这是一个遗留设置。 最佳实践是使用 File 端口 来管理本地文件系统,而不是此设置。
消息
消息设置 确定端口如何搜索消息并在处理后管理它们。 可以将消息保存到你的 已发送 文件夹,或者可以根据 已发送 文件夹方案将它们保存,如下所述。
- 保存至 Sent 文件夹 选中此选项可将端口处理的文件复制到端口的已发送文件夹中。
- 已发送文件夹方案 端口根据选定的时间间隔对已发送文件夹中的文件进行分组。例如,选项每周(Weekly)指示端口每周创建一个新的子文件夹,并将本周发送的所有文件存储在该文件夹中。空白设置告诉端口将所有文件直接保存在“Sent”文件夹中。对于处理许多事务的端口,使用子文件夹可以帮助保持文件有序并提高性能。
日志
- 日志级别 端口生成的日志的详细程度。 当端口请求支持时,请将其设置为 调试。
- 日志子文件夹方案 指端口根据选定的时间间隔对日志文件夹中的文件进行分组。 例如,Weekly 选项表示端口每周创建一个新子文件夹并将该周的所有日志存储在该文件夹中。 空白设置告诉端口将所有日志直接保存在 Logs 文件夹中。 对于处理大量事务的端口,使用子文件夹有助于保持日志井井有条并提高性能。
- 保留消息副本 选中此项可使已处理文件的日志条目包含文件本身的副本。 如果禁用此功能,端口可能无法从 输入 或 输出 选项卡下载文件的副本。
特殊设置
特殊设置 适用于特定用例。
- 其他设置 允许在以分号分隔的列表中配置隐藏的端口设置,例如
setting1=value1;setting2=value2。 正常的端口用例和功能不需要使用这些设置。
自动化
- 发送 到达端口的文件是否将会被自动处理。
性能
与端口资源分配相关的设置。
- 最大工作线程数 此端口上处理文件时从线程池中消耗的最大工作线程数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
- 最大文件数 分配给端口的每个线程发送的最大文件数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
通知
与配置警报和服务等级协议 (SLA) 相关的设置。
端口邮件设置
在执行 SLA 之前,需要设置电子邮件警报以获取通知。 单击 配置通知 将打开一个新的浏览器窗口,转到 系统设置,可以在其中设置系统范围的警报。 有关详细信息,请参阅通知。
服务等级协议 (SLA) 配置
SLA 能够配置期望工作流中的端口发送或接收的数量,并设置期望满足该数量的时间范围。 知行之桥在不满足 SLA 时发送电子邮件警告用户,并将 SLA 标记为 有风险,这意味着如果很快不满足 SLA,则会将其标记为 已违反。 这使用户有机会介入并确定未满足 SLA 的原因,并采取适当的措施。 如果在风险时间段结束时仍未满足 SLA,则将 SLA 标记为违反,并再次通知用户。
要定义 SLA,请单击 添加预期数量条件。
- 如果端口具有单独的发送和接收操作,请使用单选按钮指定 SLA 所属的方向。
- 将 期待至少 设置为期望处理的最小交易数量(交易量),然后使用 每 字段指定时间范围。
- 默认情况下,SLA 每天都有效。 要更改此设置,请取消选中每日,然后选中想要的一周中的几天的框。
- 使用 将状态设置为“有风险” 来指示何时应将 SLA 标记为存在风险。
- 默认情况下,在违反 SLA 之前不会发送通知。 要更改此设置,请选中 发送“有风险”通知。
以下示例显示为预计周一至周五每天接收 1000 个文件的端口配置的 SLA。 如果尚未收到 1000 个文件,则会在该时间段结束前 1 小时发送风险通知。

定义平面文件格式
配置 Flat File 端口的第一步就是定义平面文件的格式。本部分介绍具有单行类型的格式,换句话说,平面文件中的每一行都具有相同的字段集。对于有多个不同行类型的平面文件,请查阅多种行类型 部分。
Character Delimited 的单行格式
对于 Character Delimited 的平面文件,定义格式很简单:通过分隔符属性指定平面文件中分隔不同字段的字符。
当前列标题 字段说明了平面文件中的第一行是否是标题行;换句话说,它包含了字段名称而不是实际数据。如果这些列标题存在,端口将会使用这些标题名称作为最终转换成的 XML 中的 XML 元素名。
如果列标题不存在,端口支持通过在行类型中添加字段,手动指定每一个字段的名称。这些字段名称按照索引顺序应用,意味着行类型中的第一个条目将会是平面文件行中第一个字段的名称,以此类推。
端口也可以通过启用使用自动生成的字段名称来自动生成通用的字段名称。
Position Delimited 的单行格式
对于 Position Delimited 的平面文件,定义格式需要指定在格式中每个字段的位置。端口设置中行类型部分为平面文件中存在的行增加任意数量的字段。每个字段必须使用名称和其在平面文件中出现的位置进行标识。
当前列标题 字段表明了平面文件中的第一行是否为标题行;换句话说,它包括了字段名称而不是实际数据。字段名称仍然需要在行类型部分中配置,且这个设置简单地保证了标题行不被识别为实际数据。
非标准 XML 控制字段
平面文件数据可能包含包含完全数字或以数字开头的控制字段的行。虽然这在平面文件数据中很正常,但在将该平面文件数据转换为 XML 时却带来了挑战,因为 XML 元素不能以数字开头。它们必须以字母或下划线开头。为了在平面文件端口中适应这种情况,如果控制字段以数字开头,知行之桥会自动在输出 XML 中的该值前面添加两个下划线 (__)。此外,还会向该元素添加一个 lineType 属性,其值对应于原始控制字段值。例如,以下平面文件数据包括两种线型,控制字段分别为 000 和 111:
000 12345 01222025 NC Yes
000 02468 01242025 MD Yes
111 82390 01202025 FL No
111 67524 01132025 CO No
此数据的平面文件配置如下所示:
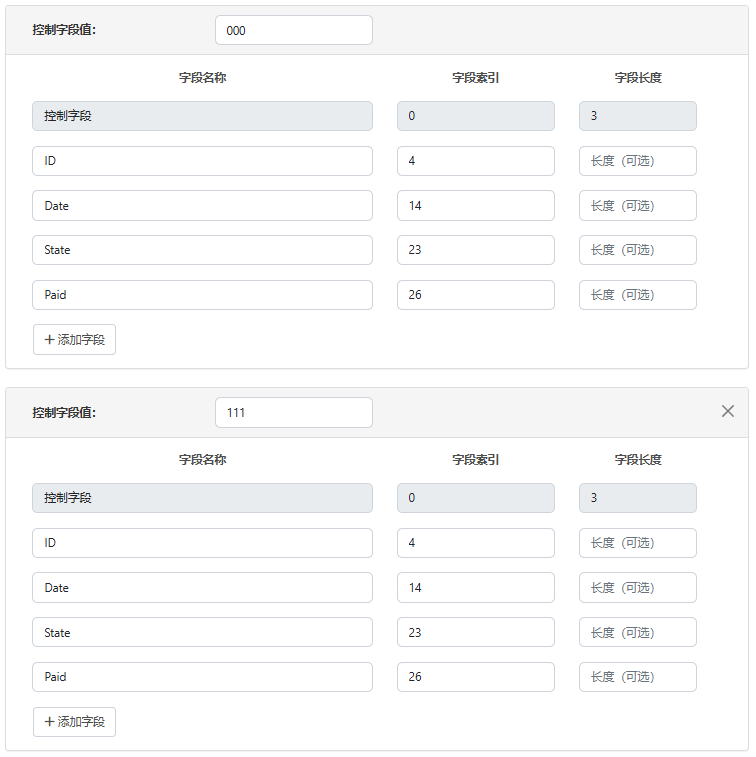
当使用此配置通过端口运行此平面文件数据时,输出如下所示:
<Items>
<__000 lineType="000">
<ID>12345</ID>
<Date>01222025</Date>
<State>NC</State>
<Paid>Yes</Paid>
</__000>
<__000 lineType="000">
<ID>02468</ID>
<Date>01242025</Date>
<State>MD</State>
<Paid>Yes</Paid>
</__000>
<__111 lineType="111">
<ID>82390</ID>
<Date>01202025</Date>
<State>FL</State>
<Paid>No</Paid>
</__111>
<__111 lineType="111">
<ID>67524</ID>
<Date>01132025</Date>
<State>CO</State>
<Paid>No</Paid>
</__111>
</Items>
请注意,每种线型都带有两个下划线前缀,并且 XML 元素具有与原始控制字段值相对应的 lineType 属性。这允许平面文件数据和 XML 完全双向,这意味着当输出 XML 作为输入传递到平面文件端口时,输出是包含正确线型定义且不带任何下划线的平面文件数据。
这也意味着,如果要从 XML 转到平面文件,并且需要以数字开头(或全部为数字)的线型控制字段,则需要在文档到达平面文件端口之前,在文档映射中的相应 XML 元素上实现 lineType XML 属性。
多种行类型
如果平面文件格式包括了多种行类型,多行模式属性应该被启用。平面文件中标识行类型的字段被称为控制字段。
Character Delimited 的多种行类型
当文件类型为 Character Delimited,字段参数设置决定了控制字段出现在平面文件中每一行地位置。该索引从 0 开始,意味着如果控制字段是行中的第 5 个值,那么字段索引就应该是 4。
对于可能出现在控制字段的每个值,在端口设置行类型单击增加行类型按钮。标识行类型的值应该在该行的控制字段值中设置。
一旦每个可能的行类型通过特定的控制字段值被添加和标识,在每行中将出现的字段应根据索引顺序指定。
如果生成字段/行类型名称启用,为在平面文件中存在的所有字段或行类型(只有控制字段必需)提供名称和索引是必需的。在这种情况下,端口将会为任何未定义的字段或行类型自动生成 XML 元素。
Position Delimited 的多种行类型
当文件类型是 Position Delimited,起始索引设置决定了控制字段在平面文件中每一行出现(开始)的位置。这个索引从 0 开始,意味着如果控制字段从行中第 15 个字符开始,那么字段索引就应该是 14。
对于可能出现在控制字段的每个值,在端口设置行类型单击增加行类型按钮。标识行类型的值应该在该行的控制字段值中设置。
一旦每个可能的行类型通过特定的控制字段值被添加和标识,在每行中将出现的字段应根据所处(开始)的位置指定。
多行示例
例如,某个平面文件包括两种类型的行,一个 shipment 行和一个 package 行。shipment 行包括发货的日期、时间和地址信息,package 行类型包括了发货的项目信息。
shipment 行可能有一个值为 “SHIP” 的控制字段值,package 行可能有一个值为 “PCKG” 的控制字段值。每一行的第一个字段是 “SHIP” 或 “PCKG” 来说表明该行是什么类型。
针对这种情况,多行模式应该被启用,且字段索引(或起始索引)应设置为 0,表明控制字段是该行中的第一个字段。然后,在行类型部分应该配置有两种行类型;一种控制字段值为 “SHIP”,包括 shipment 行的每个字段(例如发货日期,交付日期,收货地址等),一种控制字段值为 “PCGK”,包括 package 行的每个字段(例如项目名称,项目重量等)。
XML 格式
在平面文件转换为 XML 文件之后,结果应有如下的 XML 结构:
- 位于文件根部的 Items 元素
- 平面文件中的每一行有一个与该行控制字段值相同的元素(如果未定义控制字段值,则是“行”)
- 行中的每个字段是控制字段值元素的子元素
例如,如果平面文件有 “SHIP” 和 “PCKG” 行,那么输出的 XML 会和此格式相似:
<Items>
<SHIP>
<ShipmentId>12B992</ShipmentId>
<Date>20200228</Date>
<ShipTo>14 Wallaby Way</ShipTo>
</SHIP>
<PCKG>
<ShipmentId>12B992</ShipmentId>
<ItemName>Goggles</ItemName>
<ItemWeight>3.98</ItemWeight>
</PCKG>
<PCKG>
<ShipmentId>12B992</ShipmentId>
<ItemName>Fins</ItemName>
<ItemWeight>1.07</ItemWeight>
</PCKG>
</Items>
转换 XML 文件为平面文件,输入的 XML 必须与上面的结构匹配(包括字段名称必须与端口配置中定义的字段匹配的限制)。
转换 XML 文件为平面文件,端口将在最终的平面文件中为每个 row 元素创建一个新行。对于 row 元素的每个子元素,端口将会将其与端口配置中字段名称匹配, 并将该元素放到合适的字段索引。
多行层级关系
有多种行类型的平面文件通常在行类型中有隐含的层级结构。例如,一行包括订单的信息(例如客户名称,订单日期等),下面几行代表订单中的每个订单行(例如项目名称,项目数量等)。行项目“属于”订单,构成层级关系。
这些关系有时称为“主-明细”关系;意味着第一个行类型(订单)是主,下面几行(行项目)是关于主行的“明细”信息。在 XML 中,这通常表现为“父子”关系。
Flat File 端口在转换平面文件为 XML 时可以保留这些层级关系。如果高级中的嵌套行类型启用,端口将自动缩进“明细”行,这样它们就可以称为“主”行类型的子元素。
以下是将嵌套行类型设为 true,转换一个有层级关系的平面文件的示例。在示例之后的部分将解释端口决定层级关系使用的逻辑。
多行层级关系示例
以输入以下平面文件为例:
M,CustomerA,05022020,true
D,itemA,4,2.09
D,itemB,9,15.23
M,CustomerB,05032020,false
D,itemC,1,5.99
D,itemE,1,3.99
平面文件中有两个行类型,M 和 D:
- M, 或者说是主,包括一个订单的信息:客户名称,订单日期,以及一个“重要客户”的标识
- D, 或者说明细,包括了之前订单的订单行信息:项目名称,项目数量,项目价格
因为 D 行类型“属于” M 行类型,两者为层级关系,那么在转换平面文件为 XML 时,需要将层级关系保留下来。要查看其格式,请在转换上文平面文件为 XML 时,启用嵌套行类型,采取以下示例输出:
<Items>
<M>
<CustomerName>CustomerA</CustomerName>
<OrderDate>05022020</OrderDate>
<HighValueCustomer>true</HighValueCustomer>
<D>
<ItemName>itemA</ItemName>
<ItemQuantity>4</ItemQuantity>
<ItemPrice>2.09</ItemPrice>
</D>
<D>
<ItemName>itemB</ItemName>
<ItemQuantity>9</ItemQuantity>
<ItemPrice>15.23</ItemPrice>
</D>
</M>
<M>
<CustomerName>CustomerB</CustomerName>
<OrderDate>05032020</OrderDate>
<HighValueCustomer>false</HighValueCustomer>
<D>
<ItemName>itemC</ItemName>
<ItemQuantity>1</ItemQuantity>
<ItemPrice>5.99</ItemPrice>
</D>
<D>
<ItemName>itemE</ItemName>
<ItemQuantity>1</ItemQuantity>
<ItemPrice>3.99</ItemPrice>
</D>
</M>
</Items>
可以看到 D 记录为 M 记录的子元素,准确反映了源数据中存在的层级结构。
多行层级关系逻辑
Flat File 端口使用源平面文件中行的顺序决定行项目之间的层级关系。当嵌套行类型启用,端口将遵循以下逻辑:
- 端口遇到的第一个行类型通常被当作层级结构的最上级(即不会在生成的 XML 中缩进)
- 在第一个行类型之后,当端口遇到一个新的行,它假设这个行类型是前一个行类型的下的层级(即它归属于前一个行且在 XML 中缩进)
- 当端口遇到一个之前遇到过的行类型,将返回到该行类型的层级,并关闭所有等于或低于此等级的 XML 元素。
因此,源平面文件必须根据所需的层级结构按行排列。
宏
在文件命名策略中使用宏可以提高组织效率和对数据的上下文理解。 通过将宏合并到文件名中,可以动态地包含相关信息,例如标识符、时间戳和消息头信息,从而为每个文件提供有价值的上下文。 这有助于确保文件名反映对组织重要的详细信息。
知行之桥 支持这些宏,它们都使用以下语法:%Macro%。
| 宏 | 描述 |
|---|---|
| ConnectorID | 替换为端口的 ConnectorID。 |
| Ext | 替换为端口当前正在处理的文件的文件扩展名。 |
| Filename | 替换为端口当前正在处理的文件的文件名(包括扩展名)。 |
| FilenameNoExt | 替换为端口当前正在处理的文件的文件名(不带扩展名)。 |
| MessageId | 计算端口输出的消息的 MessageId。 |
| RegexFilename:pattern | 将正则表达式模式应用于端口当前正在处理的文件的文件名。 |
| Header:headername | 替换为端口正在处理的当前消息的目标消息头 (headername) 的值。 |
| LongDate | 以常规格式计算系统的当前日期时间(例如,2024 年 1 月 24 日星期三)。 |
| ShortDate | 以 yyyy-MM-dd 格式计算系统的当前日期时间(例如 2024-01-24)。 |
| DateFormat:format | 以指定格式(format)计算系统的当前日期时间。 有关可用的日期时间格式,请参阅示例日期格式 |
| Vault:vaultitem | 计算指定保管库项目的值。 |
示例
某些宏(例如 %Ext% 和 %ShortDate%)不需要参数,但其他宏则需要。 所有带有参数的宏都使用以下语法:%Macro:argument%
以下是带有参数的宏的一些示例:
- %Header:headername%:其中
headername是消息上消息头的名称。 - %Header:mycustomheader% 解析为输入消息上设置的
mycustomheader消息头的值。 - %Header:ponum% 解析为输入消息上设置的
ponum消息头的值。 - %RegexFilename:pattern%:其中“pattern”是正则表达式模式。 例如,
%RegexFilename:^([\w][A-Za-z]+)%匹配并解析为文件名中的第一个单词,并且不区分大小写(test_file.xml解析为test) 。 - %Vault:vaultitem%:其中
vaultitem是 vault 中项目的名称。 例如,%Vault:companyname%解析为存储在保管库中的companyname项的值。 - %DateFormat:format%:其中
format是可接受的日期格式(有关详细信息,请参阅示例日期格式)。 例如,%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%解析为文件上的日期和时间戳。
还可以创建更复杂的宏,如以下示例所示:
- 将多个宏组合在一个文件名中:
%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%%EXT% - 包括宏之外的文本:
MyFile_%DateFormat:yyyy-MM-dd-HH-mm-ss-fff% - 在宏中包含文本:
%DateFormat:'DateProcessed-'yyyy-MM-dd_'TimeProcessed-'HH-mm-ss%